안녕하세요 웹파트 YB 김가현입니다 !
2주차에는 조건부 렌더링, 리스트 렌더링, 컴포넌트를 순수하게 유지하기, 트리로서의 UI 이렇게 총 네 개의 챕터를 읽고 공부해봤는데요,
공식 문서를 기반으로 내용을 정리해보았습니다 😋
조건부 렌더링
- 조건에 따라 다른 항목을 표시해아할 때
- if문, && 및 ? : 연산자와 같은 자바스크립트 문법을 사용하여 조건부로 JSX를 렌더링할 수 있음
If-else 문
if (isPacked) {
return <li className="item">{name} ✅</li>;
}
return <li className="item">{name}</li>;
- 코드가 길어지는 경향이 있어 가독성이 다소 떨어질 수 있다
&&
return (
<li className="item">
{name} {isPacked && '✅'}
</li>
);
- && 앞에 있는 조건이 참이라면 뒤의 표현식을 렌더링
- 조건부 렌더링에 &&를 쓰지 말라고 ?
삼항연산자
return (
<li className="item">
{isPacked ? name + ' ✅' : name}
</li>
);- condition ? true: false
- isPacked가 참이면 name + ' ✅'을 렌더링하고, 그렇지 않으면 name을 렌더링
리스트 렌더링
데이터를 JavaScript 객체와 배열에 저장하고 map(), filter() 같은 메서드를 사용하여 해당 객체에서 컴포넌트 리스트를 렌더링할 수 있다
map()
const fruits = ['apple', 'banana', 'orange'];
function FruitList() {
return (
<ul>
{fruits.map((fruit, index) => (
<li key={index}>{fruit}</li>
))}
</ul>
);
}
export default FruitList;
filter()
import React from 'react';
function FruitList() {
const fruits = [
{ id: 1, name: 'Apple', isInShoppingList: true },
{ id: 2, name: 'Banana', isInShoppingList: false },
{ id: 3, name: 'Orange', isInShoppingList: true },
];
const shoppingList = fruits.filter(item => item.isInShoppingList);
return (
<ul>
{shoppingList.map(item => (
<li key={item.id}>{item.name}</li>
))}
</ul>
);
}
export default FruitList;
+) React 배열의 key 속성 ❓
React에서 리스트를 렌더링할 때는 각 항목에 고유한 key 속성을 제공해야 한다 !
key 속성은 React가 어떤 항목을 변경, 추가, 또는 삭제할지 식별하는 것을 돕는 역할을 하는데, 이 key 속성은 해당 데이터가 가지는 고유한 값을 사용해야 한다. 일반적으로 데이터의 ID를 key로 사용하지만 리스트 항목에 고유한 ID가 없는 경우에는 항목의 인덱스를 key로 사용할 수 있다.
컴포넌트를 순수하게 유지하기
리액트는 순수 함수를 이용하여 UI를 렌더링한다. 즉, 컴포넌트를 순수 함수로 구성하려고 한다
순수 함수란 무엇이며, 왜 컴포넌트를 순수 함수로 구성하려고 하는 것일까 ?
순수 함수란 ?
- 동일한 인수를 전달하면 항상 동일한 결과를 반환하는 함수 (수학 공식 같은 !)
- 같은 입력이 들어오면 항상 같은 결과를 반환하며, 내부 상태가 변하지 않으면 렌더링을 반복하지 않음
왜 리액트는 컴포넌트를 순수 함수로 구성하려고 할까 ?
리액트의 컴포넌트는 순수 함수와 유사한 특성을 가지고 있다.
컴포넌트는 props와 state를 입력받고, React 엘리먼트를 반환하는데, 동일한 props와 state를 입력받으면 항상 동일한 엘리먼트를 반환한다. 리액트에서 순수 함수를 기반으로 하는 함수형 컴포넌트를 권장하는 이유는 아래와 같다.
- 예측 가능성 - 동일한 props 전달 시 동일한 결과 반환 . 예측 가능한 동작 보장
- 성능 최적화 - props가 변경되지 않은 경우 렌더링을 건너뛸 수 있으므로 성능 최적화 가능
- 테스트 용이성 - 입력에 따라 항상 동일한 결과를 반환하기 때문에 테스트하기 쉬움
- 유지보수성 - 코드의 의도를 명확하게 표현할 수 있으므로 유지보수성이 높아짐
그러나 모든 컴포넌트가 항상 순수 함수로 만들 수 있는 것은 아니다 !
외부 API를 호출하여 해당 데이터를 사용하는 컴포넌트나 브라우저 이벤트에 의존하는 컴포넌트 등은 side effect 가 발생할 수 밖에 없다.
이런 경우는 useEffect 훅이나 상태 관리 라이브러리 (redux, recoil 등 ..) 을 사용하는 것이 좋다
리액트에서의 사이드 이펙트(Side Effect)
의도치 않게 발생하는 예측할 수 없는 효과들을 의미한다.
만약 함수 내부에서 수행되는 작업이 외부 상태를 변경하거나 외부의 입력에 영향을 미친다면 이는 사이드 이펙트가 발생하는 것이다.
사이드 이펙트는 원래의 목적과 다르게 발생하기 때문에 사이드 이펙트가 발생하지 않도록 주의해야 한다.
let guest = 0;
function Cup() {
guest = guest + 1;
return <h2>Tea cup for guest #{guest}</h2>;
}
export default function TeaSet() {
return (
<>
<Cup />
<Cup />
<Cup />
</>
);
}
Cup 컴포넌트는 사이드 이펙트를 발생시키고 있다 💥 외부 변수 guest의 값을 직접 변경하고 있기 때문이다.
이 컴포넌트를 여러 번 호출하면 다른 JSX가 생성되며, 다른 컴포넌트가 guest 값을 읽고자 할 때 렌더링된 시점에 따라 마찬가지로 다른 JSX를 생성하게 된다 → 예측할 수 없게 된다 ..!!!
😢 그럼 사이드 이펙트를 발생시키면 안되나요 ...?
완전히 사이드 이펙트를 피할 수는 없다 ! 거의 모든 애플리케이션은 어떤 방식으로든 상태 변경이나 외부와의 상호작용이 필요하기 때문이다.
- 서버에서 API 호출
- 함수 외부 값 변경
- 쿠키 및 브라우저 스토리지 이용
- 브라우저 직접 변경 (document,window 사용)
- 시간 관련 함수 사용 (setTimeOut, setInterval)
따라서 이를 적절히 관리하고 최소화함으로써 코드의 예측 가능성을 높이는 것이 중요하다
사이드이펙트와 이벤트 핸들러
공식문서에 따르면 리액트 내부의 로직을 2가지 형태로 나눌 수 있다고 한다.
1) 렌더링 코드
- prop이나 state로 JSX를 반환하는 렌더링 코드
- 같은 입력값이라면, 항상 같은 값을 출력해야 한다 (순수성)
2) 이벤트 핸들러
- 컴포넌트 내부의 이벤트를 핸들링하기 위한 함수
- 사용자와 상호작용하거나, HTTP 요청을 보내거나 하는 이벤트로부터 발생하는 사이드 이펙트를 처리
- 반드시 순수 함수일 필요는 없다 !
- 이벤트 핸들러는 컴포넌트 내에 정의되어 있지만, 렌더링이 된 이후의 사용자 동작(특정 이벤트가 발생할 때)에 의해 발생한다
- 이벤트가 발생한 시점이 이미 렌더링 된 이후이기 때문에 사이드 이펙트가 렌더링과 관련 없이 실행되기 때문
만약 사이드 이펙트를 처리하기 위한 적절한 이벤트 핸들러를 찾을 수 없을 때 useEffect 훅에서 렌더링 이후에 사이드 이펙트를 처리할 수 있지만 가능하면 useEffect는 최후의 수단으로 사용하는 것이 좋다
사이드 이펙트와 useEffect
이벤트 핸들러만으로 사이드 이펙트를 처리하지 못하는 경우가 발생할 수 있다.
React에서는 useEffect 훅을 제공하는데, 이를 사용하면 특정 이벤트가 아닌 렌더링 자체로 발생하는 사이드 이펙트를 명시할 수 있다.
그러나 useEffect는 최후의 수단으로 사용하는 것이 좋으며, 가능하다면 렌더링 만으로 로직을 구현해보자 !
왜 useEffect를 최후의 수단으로 사용하는 것이 좋은가 ?
1. useEffect 간의 연쇄작용
- useEffect가 늘어날수록, 각각의 의존성 배열에 따라 실행될 조건을 모두 고려해야 하기 때문에 사이드 이펙트 관리가 복잡하다
(경우의 수가 선형적으로 늘어나는 것이 아니기 때문)
2. 의도치 않은 재렌더링의 가능성 존재
3. 예측 불가능성
- 여러 개의 useEffect가 서로 상호작용하게 되면 컴포넌트의 동작을 예측하기 어려워질 수 있다.
📌 useEffect 구조
useEffect ( function, [deps] )
* function: 실행하고자 하는 콜백 함수
* deps: 의존성 배열 (검사하고자 하는 특정 값 배열)
👉 두 번째 인수로 전달한 배열[ ]의 값이 변경되면, SideEffect가 발생하여 첫 번째 인수로 전달한 콜백 함수를 실행시킨다
ex)
import React from 'react';
function Notification({ notificationCount }) {
const message = `현재 알림 수: ${notificationCount}`;
// Bad! document.title을 직접 수정
document.title = notificationCount > 0
? `(${notificationCount}) 새로운 알림이 있습니다`
: '알림이 없습니다';
return <div>{message}</div>;
}
export default Notification;
이 코드는 컴포넌트가 렌더링될 때마다 document.title을 업데이트한다.
notificationCount가 변경되지 않았어도 매 렌더링 시마다 document.title을 수정하게 되는데 이는 불필요한 브라우저 DOM 업데이트로 이어지며, 성능 측면에서도 좋지 않다.
또한 예측 가능성을 보장하기 어렵다 ! 따라서 useEffect로 분리할 필요가 있다.
import React, { useEffect } from 'react';
function Notification({ notificationCount }) {
const message = `현재 알림 수: ${notificationCount}`;
// Side-Effect 코드를 useEffect로 분리
useEffect(() => {
// 알림 개수에 따라 document.title 업데이트
if (notificationCount > 0) {
document.title = `(${notificationCount}) 새로운 알림이 있습니다`;
} else {
document.title = '알림이 없습니다';
}
}, [notificationCount]); // notificationCount가 변경될 때마다 실행
return <div>{message}</div>;
}
export default Notification;
useEffect로 분리하면 의존성 배열에 따라 notificationCount 값이 바뀔 때만 document.title을 변경하므로, 불필요한 렌더링을 피하면서도 사이드 이펙트를 처리할 수 있다.
+) 읽어보면 좋을 것 같은 아티클 😋
useEffect 잘못 쓰고 계신겁니다.
고혈압을 10분만에 예방하세요.
velog.io
트리로서의 UI
리액트가 앱의 컴포넌트 구조를 어떻게 추적할까 ?
브라우저가 HTML과 CSS를 모델링하는데 트리 구조를 사용한 것처럼, 리액트도 앱 안에서 컴포넌트 간의 관계를 관리하고 모델링하기 위해 트리 구조를 사용한다.
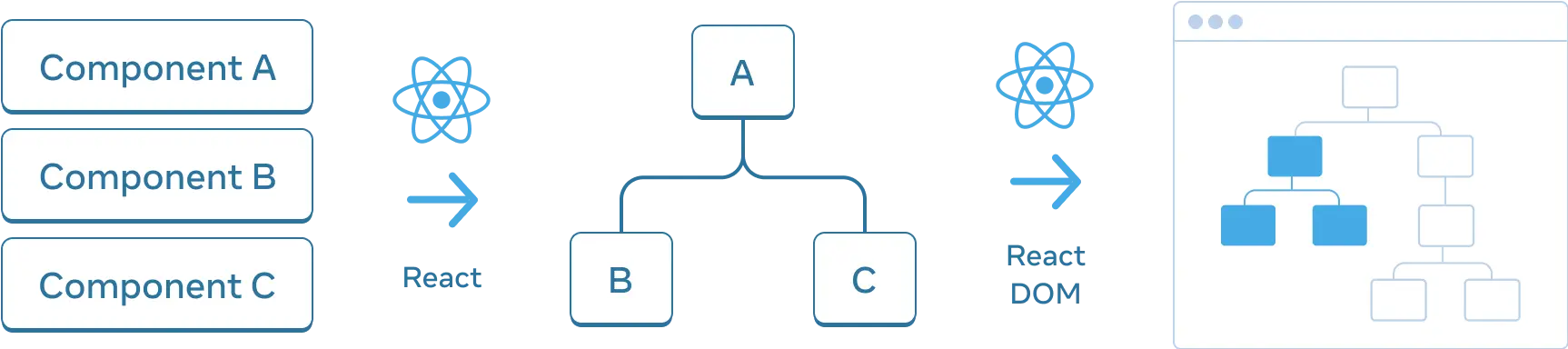
렌더 트리
컴포넌트의 주요한 특성 중 하나는 컴포넌트를 중첩하여 사용할 수 있다는 것이다. (부모 컴포넌트, 자식 컴포넌트)
리액트 앱을 렌더링 할 때 이 관계를 렌더 트리에서 모델링한다.
import FancyText from './FancyText';
import InspirationGenerator from './InspirationGenerator';
import Copyright from './Copyright';
export default function App() {
return (
<>
<FancyText title text="Get Inspired App" />
<InspirationGenerator>
<Copyright year={2004} />
</InspirationGenerator>
</>
);
}import * as React from 'react';
import inspirations from './inspirations';
import FancyText from './FancyText';
import Color from './Color';
export default function InspirationGenerator({children}) {
const [index, setIndex] = React.useState(0);
const inspiration = inspirations[index];
const next = () => setIndex((index + 1) % inspirations.length);
return (
<>
<p>Your inspirational {inspiration.type} is:</p>
{inspiration.type === 'quote'
? <FancyText text={inspiration.value} />
: <Color value={inspiration.value} />}
<button onClick={next}>Inspire me again</button>
{children}
</>
);
}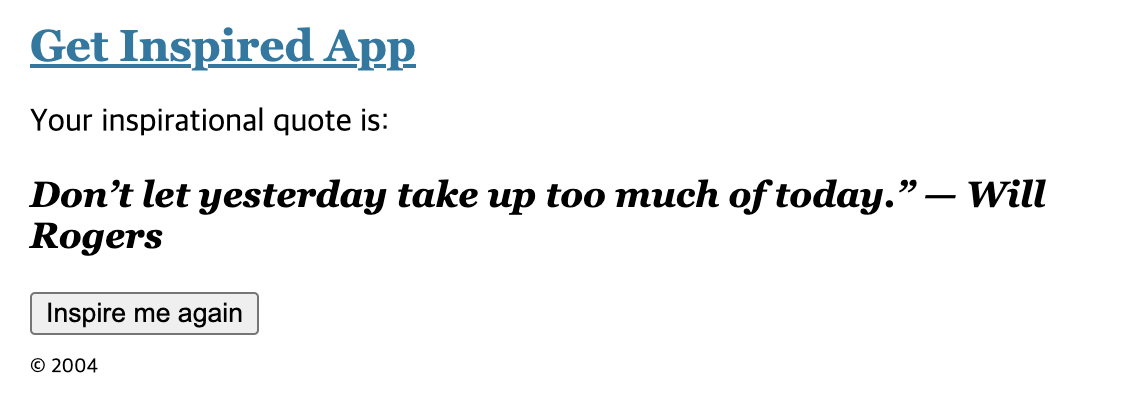
렌더 트리를 그려보면 ?
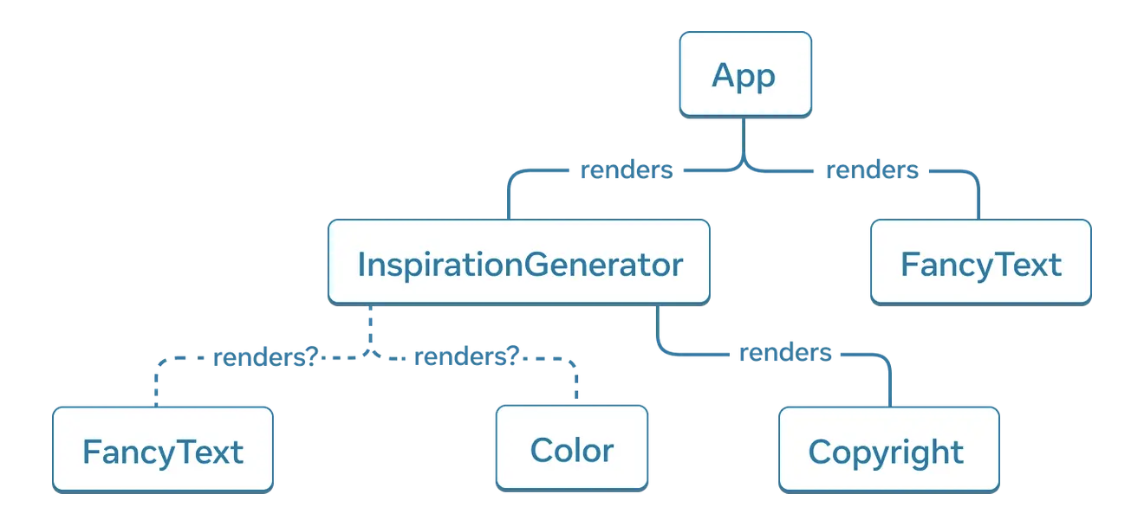
inspiration.type이 무엇이냐에 따라 <FancyText> 또는 <Color>를 렌더링 하므로 위와 같은 형태로 그릴 수 있다.
리액트 렌더 트리의 루트 노드는 앱의 루트 컴포넌트이며, 가장 먼저 렌더링하는 컴포넌트이다.
최상위 컴포넌트는 루트 컴포넌트와 제일 근접한 컴포넌트이고 아래에 있는 모든 컴포넌트의 렌더링 성능에 영향을 미치며 일반적으로 가장 복잡성이 높다.
리프 컴포넌트는 트리의 최하위에 위치하고, 자식 컴포넌트가 없으며 보통은 가장 자주 리렌더링 된다.
이렇게 렌더 트리를 살펴보는 것은, 데이터의 흐름을 파악하는 데 도움이 된다 !
모듈 의존성 트리
React 앱의 모듈 의존성을 나타낸다.

- 애플리케이션의 모듈을 어떻게 결합하고 로딩할지를 결정하는 데 사용
- 코드가 빌드되거나 번들링될 때 생성
- 불러오는 모듈을 모두 포함한다 (컴포넌트가 아닌 모듈도!)
- 앱의 규모가 커지면 번들 크기와 비용 증가
'나야, 리액트 스터디' 카테고리의 다른 글
| [week2] 리액트의 트리구조 (6) | 2024.11.04 |
|---|---|
| [week2] 컴포넌트의 순수성 (3) | 2024.11.03 |
| [week2] 순수 컴포넌트, 사이드 이펙트, 트리로서 UI (5) | 2024.11.03 |
| [week2] 순수 컴포넌트 (5) | 2024.11.03 |
| [week2] - 조건부 렌더링, 리스트 렌더링, 컴포넌트를 순수하게 유지하기, 트리로서의 UI (2) | 2024.11.03 |

